What is Data Mesh Anyway?

TLDR;
While the term is relatively new, Data Mesh as a concept existed for decades. In this article, narrated in a fable format, you will learn how the data systems evolved, how distributed data systems gave rise to Data Mesh and why we need them.
Background
It was an early in the morning late winter morning. Debby, the chief data systems architect at Acme Widgets was studying half-mindedly the swirling steam coming up her cup of joe and contemplating how to attack the day looking at her calendar. She has been around the block for almost two and half decades, has seen the hypes getting formed and dissipate like the dew drops outside her window. She reflected on how she has had to educate many executives to make the right decisions in her career. As a leader in data ecosystems, she is fully aware of how her world is frighteningly close to data corruption if not designed correctly. While some in the powers that be understand it, some get drowned in the ocean of buzzwords and don’t grasp the concepts clearly. In those unfortunate cases Debby painstaking but resolutely ensured she brings clarity to the discussion and helped everyone align on the right path.
Almost as if on a cue her phone rang. It was Ted, the CTO of the company, asking her to drop everything and to get on a video conference call. On the call were many top executives including Ted. “I just heard about this wonderful concept called Data Mesh”, starts Ted after thanking Debby for joining the call. “And we in the executive committee are perplexed: why are we not using it?”
Debby sighed. Distilling concepts of data management had always been a bit challenging; but it has been particularly so in the era of video conferencing thanks to the pandemic that has redefined the workplace lately. Without wasting a single second, she answered, “But of course, Ted, we are using it”.
“Huh?” asks the Aaron, the Chief Architect of the company. “I don’t remember seeing a single document that drives this concept at a high level.”
“Debby always knows her stuff and this time likely be no exception,” suggests Ted. “Why don’t you give us an overview of this concept, why it is useful and how we are using it in Acme?”
Over her entire career Debby has been championing clear thinking amidst the swirling jargons, using advancement in technology to drive strategy instead of shoehorning the strategy to fit into some buzzword. Now, she realizes, is such a moment.
Evolution of Data Systems
To understand the concept a bit clearly, Debby started with the evolution of the data systems. Before the advent of relational systems in the 1970’s, she explains, the data stored in a file was an appendage of the application. There was no shared data systems, as shown in Fig 1. There could have been multiple applications accessing those files; but all the applications were part of a family. Only that application, often called a program, understood how the data is structured in the file. The term schema had not evolve yet; but if it were, it would have been limited to that family of application a To alone. To access the data from that set of files, you would had to know about the exact schema defined in those applications; but most important, you would had to write a program to access the data.

This, Debby continues, led to two problems:
The data was location specific. For instance, you would have had to know that you were expecting to get balance of account number 123, you will need to read the 51st column from the 100th record from the 23rd file. If a new record were to be added, the 100th record might have become 101st and the file might have become 24th. A data consumer would have had to know the location such as the specific file and the relative position of the record. Similarly if a new column were to be added, the 51st column could have become 52nd, forcing your understanding the change as well.
You would had to write a program every time you wanted the data. Most data users were not programmers; so they had to rely on the programmers to get them the data they needed. The programmer pool was limited and so was this approach. Hence the data access was almost always for programmatic and processing oriented rather than adhoc analysis. In other words, data was just a bunch of text to be used by programs; not for consumers to glean meaningful insights.
The Evolution of SQL
In 1970s, Debby continues, a major breakthrough happened — a new concept was introduced called a “database”, more specifically a relational database based on a research paper in IBM. It altered the current thought process dramatically. It resulted in introduction of two powerful concepts.
First, it still used files to store data; but it separated the physical location of the data from the logical presentation. For instance, to read the balance of account 123, shown in the previous section, the user did not have to know the exact location, i.e. the file, record and column position. The user simply asked for the information and the system translated the exact location that could be found and returned the value, as shown in Fig 2.
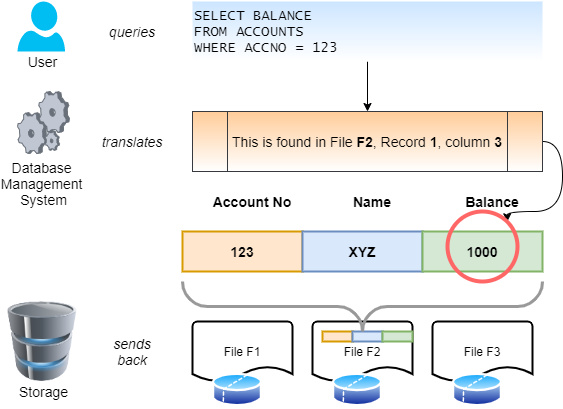
“Sort of like the DNS where an address like acmewidgets.com actually points to a numeric IP address?” ponders Ted.
“Exactly,” confirms Debby. It translated the request to actual location, read it and returned the value to the user. Similarly when a new record or a new column is introduced, it simply made the change in the file keeping it abstracted from the user. This gave rise to a new type of system called a Database Management System. Almost all modern data systems follow this principle. The database management system also moved the records or files around to the most optimal location for performance and reliability without with complete opacity to the end user.
Second, it introduced a new language called Structured Query Language (SQL) to read and write data, which is very English-like. Most business users learned it quickly and could get the data without the reliance on a program. This led to a whole new concept called adhoc data analysis. In short, SQL brought the data and users much closer and allowed the value in data to be unlocked significantly.
Distributed Databases
The database management systems, Debby continued, grew in popularity and prominence. She was careful in not using the words relational database systems. While relational was a huge part of the proliferation, the concept of database systems transcends relational. At the core of it, all database management systems do the same thing: they abstract the actual storage to varying degrees and make it extremely easy for the users to get the data they want. Hence she used the term databases to mean any type of database management systems — relational or not.
Since database systems made it easy for users to get the data they need to function, the databases proliferated. Soon there were multiple databases in a single company, each one built for a specific purpose or for a department. For instance, there was a database for Finance department for the use of those in that specific department. And there was a different one in Sales used by users there, as shown in Fig 3.
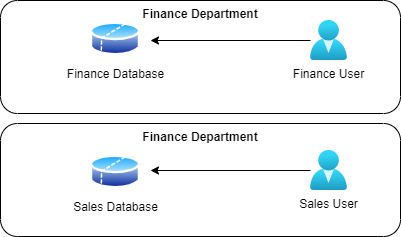
This worked well as the databases were divided along functional or departmental boundaries. But soon it became a victim of its own success, Debby explains. Suddenly people realized that they could do a whole lot of analysis with the data at the disposal, only if they had access to it. For instance some folks in Finance department felt they really couldn’t do forecasting since they never had access to the data from Sales. What if they had data from Sales, and all other departments while at it? They would have been able to perform their jobs more effectively.
Data Landscape expanded the access to multiple datastores in two different ways: Copy and Bridge.
Data Copy
The data landscape, Debby continues, evolved into two paths. First path was copying the data from one database to other. So, the Sales database was to send a snapshot of relevant data to Finance database. While this worked, this violated a fundamental concept in data management: thou shalt hold only one copy of data. Creating a copy created all types of issues, for instance losing track of which copy was the most recent, or worse, how was that copy even made. There was no guaranty that the copy was made with some transformation and if that transformation was even accurate. Here is a simple example. The Sales Database stores the prospect of sales in a 1–5 scale where 5 is the highest probability of sales. However when copying the data, the data engineer mistakenly assumed it was a “rank”, i.e. 1 is better than 5 and created a ranking description from the 1–5 values. The mistake was simple but the results were devastating. The meaning of data now became completely different. Hence the copy was not a great idea.
Data Bridge
To eliminate the need for the copy, Debby elaborates, database vendors provided bridges to other databases to show the data in real time. Pointing to Fig 4, she explains how there is an actual table in Sales Database which the users in Finance are interested in. Instead of copying that data, the Sales database administrators simply created a bridge over which a pointer could be created in the Finance Database. When the users in Finance selected data from that pointer, it actually went over the bridge and pulled data in real time from Sales. This solved the problem of getting stale data and also eliminated copies. One example was database links in Oracle.
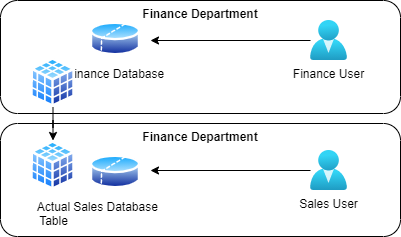
“This,” Debby clarified “is sometimes known a distributed database system where the data used by applications and users are spread over multiple databases but still available from one.”
“Sounds like a reasonable solution”, the audience muses. “What went wrong?”
The problems, Debby explains, are many:
- This is usually a vendor specific solution. The databases need to be on the same vendor’s platform for this bridge to work in many cases.
- Sometimes the vendors allow exposing the data from another vendor’s database; but that is limited to only the supported file types, e.g. external tables in Hadoop on Parquet files. But the interoperability is limited.
- Even in those cases the recipient database may need to interpret the files, a process known as serialization/deserialization (serde), which reduces performance and negates the advantages of a database engine.
However, if an organization standardized on a single database vendor, it was possible to create a truly distributed database platform.
“But”, counters Aaron, “isn’t the whole point of database platform being the best for that purpose? Going to a single vendor for all types of database needs completely destroys that concept.”
Rise of the Warehouse
“Precisely”, agrees Debby. “This is why this approach was not very successful. Many database vendors produced fit for purpose systems. There were other types of databases such as NoSQL, Document, Time Series, Graph, etc. Choosing a single technology for all needs of a typical organization was impractical.”
So the industry looked forward. Since the 1990s another concept was coming to the data landscape — data warehouses. More precisely, the concept was analytical processing, as opposed to transactional processing that was common for data systems until then. A warehouse was built along an offshoot of relational model called a dimensional model. The big difference between the two was that with dimensional model, only a few tables (called “fact”) are allowed to grow to capture the details while the other types of data which does not change as much are allowed to stored in tables known as “dimension” tables. This design was great for boosting performance for analytical processing and hence needed different types of technology.
“Can you give some examples of what were the different types of technology?” asks Ted.
In a typical relational database systems for transaction processing, Debby explains, the data is stored in records with each record as an amalgamation of columns packed together, as shown in the left side of Fig 5, under the label Row Database.
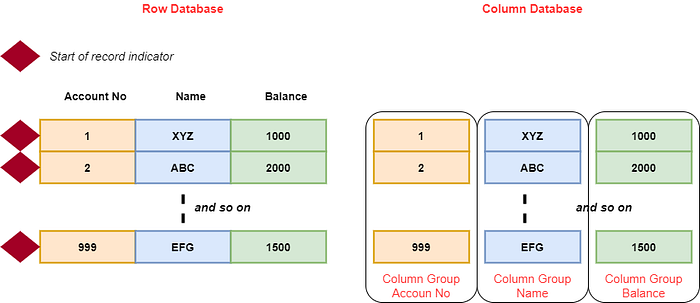
Pointing to the figure, Debby explains that the row database has 999 rows and each row is marked by a “start of row” marker. That’s how the database system knows where the records are split from each other. The other type of database called Column Database, shown on the right hand side of the Fig 5. The database does not store the data as records; but as columns. In this case, it takes all the values of the column called Account No and creates a column group in that name. Then it repeats the process for all the other columns.
“But why,” asks a clearly intrigued Aaron.
“Remember, a typical analytical query asks for an aggregation function, e.g. total of all balances, or average, min, max, etc.” Debby explains. “In case of a row database, the system has to find the beginning of record marker, locates the column, gets the value, repeats it for all rows. This takes a lot of time. In a columnar database, it gets the entire column values in one shot and applies the aggregation function, making the process orders of magnitude faster.”
So, muses Ted, why all relational database technologies are designed with this columnar approach.
Referring back to the figure 5, Debby points to the row database. In a transactional system, the applications and users typically select a small number of rows but all the columns. Since all the columns are selected, the system will have to read all the column groups and select a few rows from them. This will affect the performance significantly. Similarly updates and deletes of individual records are common in transactional systems but not warehouses; hence a columnar design would have hurt the transactional systems.
Columnar systems are optimized for aggregate queries while transactional systems are optimized for individual record access.
Warehouses also have additional optimizing features such as storage indexes, bitmap indexes, etc. to make the analytical queries faster. The audience understood why the systems need to be tooled differently.
When the fit for purpose analytical platforms were built, organizations needed it to be hydrated with data from various operational systems, as shown in Fig 6.
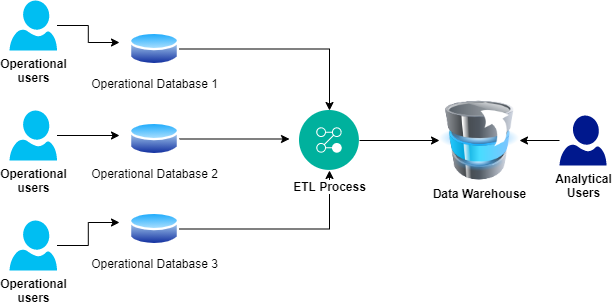
In this approach, the data is extracted from the source systems, transformed and loaded into a single datawarehouse. This decouples the technologies used for the operational databases from that of the warehouse. The analytical users access the warehouse as much as they need to and the warehouse is built with the proper technology.
This made everyone happy until about the 2010’s, Debby says. Why ? What happened then— the audience was perplexed.
Problems with a Single Warehouse
The single warehouse solved many problems, Debby continues:
- The technology is fit for purpose, leaving the right technology for the operational systems.
- The analytical users do not affect the performance of the operational systems
- The analytical platforms could apply some transformation to fix data for better understanding. For instance, while the operational systems may have been storing 0 and 1 as Inactive and Active, the warehouse could store the actual descriptive values to avoid misinterpretation.
However, there are limitations, as Debby continues:
- The warehouse is always a copy. The data there is never most recent. The data is as current as the most recent ETL job.
- The concept of a single data warehouse simply wasn’t practical for some organizations, leading to multiple warehouses. The reasons: the scale was too huge for a single warehouse, the organizational boundaries required data to be placed in multiple warehouses, regulatory requirements dictated the creation of warehouses across geographic boundaries, e.g. data of a specific country needed to be within the borders of that country, etc.
Here Comes Data Lake
But one of the most important problems, Debby quips, was the need to store unstructured data, which led to the emergence of another concept: Data Lake.
Data Lake, Debby explains, is very similar to warehouse in the sense that it is for analytical purposes as well. However, the Lake is much more flexible in the kinds of data it can accept and store, even completely unstructured data. Typically, data warehouses are structured and have specialized software to optimize data placement and access while lakes are unstructured and use non-proprietary software, which obviously reduces cost; but does not optimize the data access. The cost factor is usually a significant one when deciding between the two formats. The lower cost allows organizations to store data for the longer term cheaply.
“So,” summarizes Ted, “Warehouses are structured, have proprietary software and data formats and hence have better performance. Lakes are unstructured, have no proprietary software and hence lack in performance; but that makes them less expensive and flexible to accept any types of data. Did I sum it correctly?”
In a nutshell, Debby agrees, yes; however the lines have been blurred. Datawarehouses with proprietary software can also store non-proprietary format data as external tables. However the performance is not at par with the warehouse and the costs could be elevated. Hence many organizations follow a dual pattern:
- Lakes for long term data stores, unstructured storage, analytical needs where performance is less of a concern. Archival systems, getting access to the long term data for Machine Learning, etc. fall into this category.
- Warehouses for short term, medium to high access data and where performance is necessary. Short term reporting or Business Intelligence functions and what-if analyses play well here.
In general, compared to data warehouses, data lakes offer much cheaper but less performant solution that may be acceptable in many cases.
Debby acknowledges that some vendors actually offer both capabilities in their product; but stresses that the functionalities are different. In addition, like the previous case of datawarehouses, an organization can also create multiple data lakes to address concerns of security, geographic preference, technology, vendor’s cloud platform and so on. Not a single size fits all; so most organizations have multiple platforms for lakes and warehouses.
Introducing the Data Mesh
“I got it,” proclaims Aaron. “But how is it related to the Data Mesh we were talking about?”
The point is, Debby smiles, there are many different databases and datastores now. Multiple datawarehouses, multiple data lakes and multiple operational systems are all available as potential data sources to the users in the organizations. A typical user may need to access data from all of them. How will they do it? Will Acme need to create an uber Datawarehouse and copy all the data from all other sources, have all analytical users access that single datastore as shown in Fig 7.
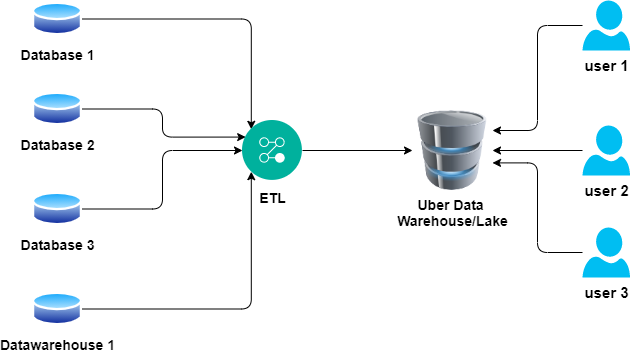
Debby let the question hang for a second there for the audience to ponder the weight of the question.
Ted speaks up. “Creating such an uber lake or warehouse is not only supremely expensive; but it adds latency making it far less attractive than going after the sources themselves. So it’s impractical as well.”
Precisely, agrees Debby. This is why Acme chose not to do that. Instead, Acme recognized that there would be multiple legitimate sources of data, each with its own unique fit for purpose technologies, data formats, etc. and customers would have the freedom to pull their desired data from the most relevant source, as shown in Fig 8.
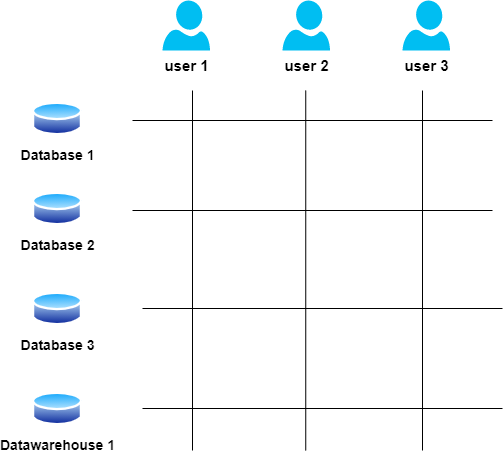
Pointing to the figure, Debby explains that there are multiple datastores accessible to all users. The data from these databases will not need to be copied to a central datawarehouse or lake.
Then Debby walks the group through the benefits:
- There is no central lake or warehouse; so the cost associated with it is no longer a concern. This cost would have been pretty significant.
- There is no latency of the data being available to the customer. Since there is no ETL to move the data to the central datatstore, the data is available immediately.
- There is no central datastore; so there is no debate about whether it should be a lake or a warehouse. Each of the datastores can be configured as a lake or a warehouse.
- Since there is no central datastore, there is no debate about technology there. Each of the datastores can store the data in the appropriate technology. For instance Database 1 can be an on-prem Hadoop cluster while Database 2 can be a cloud native datastore built for time series data.
- Each database is independently managed. The unavailability of one does not affect the access to the others.
- Each database can decide to have its own entitlement strategy. Entitlement refers to the ability of users to access the datasets they need. Each datastore may follow its own privilege management system eliminating the need to have a central authorization system.
Not such a good idea?
Aaron does not seem convinced. “These are all good reasons; but there must be something less desirable.”
Yes, there are — agrees Debby. First, it’s the last advantage — the independence of entitlements — may be a disadvantage in some cases. Since the privilege management is typically specific to the database technologies, a user’s permissions to access data needs to be managed at the datastore. This creates complexity for the user to get to the data it needs. As a corollary, it also makes it hard to determine what access should be revoked from the user when the requirements change. A single central datastore will have had a single privilege management system and hence it would have been much easier to manage the entitlements. However, Debby asserts, that a small disadvantage for Acme compared to the advantages.
The audience agrees.
“But how do users find what they are looking for among all those databases?” asks Ted.
“Aha! That a perennial problem of datastores,” smiles Debby. The answer to that? A central Data Catalog.
The audience wanted to learn more about it; but they realized the time was up. They reluctantly left the video conference call but only after Debby promised them that she would hold another session to continue this line of discussion later.
Conclusion
In summary:
- Data Mesh is simply allowing users access the most logical location for their data needs rather than copying that data to a central location.
- Each database is independently managed
- Each database can employ the best technology fit for that purpose
- The data is always current as of those datastores
- A Central Catalog and an Entitlement Process makes this setup possible.
In the next article in this series, you will learn more about the challenges with Data Mesh and Acme solved them.
